Sémantické vyhľadávanie
Vyhľadávanie a nachádzanie odpovedí na otázky sa stáva čím ďalej, tím zaujímavejšie a náročnejšie. Dôvod je neustály rast objemu dát na internete. Staré techniky vyhľadávania sú dnes už zastarané a nespĺňajú potreby, ktoré od nich používateľ požaduje. Sémantické vyhľadávanie je v súčasnosti témou číslo jeden v oblasti zlepšovania vyhľadávania, keďže ponúka vyhľadávanie v prirodzenom jazyku. Hlavnou myšlienkou sémantického vyhľadávania je porozumieť jazyku používateľa a preložiť ho do správnej formy pre vyhľadávanie. Sémantické vyhľadávanie sa sústreďuje sa pochopenie jednotlivých slov v kontexte k ostatným a tým pochopiť ich význam a spojitosť.
Aj keď sa sémantické vyhľadávanie používa zvyčajne na digitálne formy textov, našim cieľom je využiť jeho vlastnosti na digitalizované časopisy zo staršieho obdobia. Takéto dokumenty môžu veľakrát obsahovať zaujímavé, či dôležité informácie, ktoré je potrebné extrahovať a uchovať pre budúce generácie. Pre spracovanie takýchto dokumentov sme vytvorili postup, ktorý efektívne dostane texty z podoby obrazovej do takej formy, v ktorej môžeme aplikovať sémantické vyhľadávanie. Náš postup sa skladá zo štyroch, krokov, ktoré si teraz priblížime.
1. Prevod z obrázku do XML

Prvým krokom je dostať informácie uvedené na obrázku starých časopisov do textovej podoby, s ktorou sa dá pracovať. Na tento krok je použitý nástroj ABBYY FineReader, ktorý pomocou techniky OCR(Optical character recognition, čiže optické rozoznávanie znakov) spracuje náš obrazový vstup a premení ho na výstupný súbor XML. Takýto súbor uchováva informácie o paragrafoch, použitých druhoch písma, ich veľkostí a mnoho ďalšieho. Avšak ani tento nástroj nie je 100% a pri rozoznávaní dochádza k chybám.
2. Predspracovanie XML

Aby sme mohli pracovať s textom na úrovni článkom, potrebovali sme najprv predspracovať XML súbor tak, aby vo výslednej forme boli paragrafy jednotlivých článkov v rovnakých skupinách. Vykonali sme podrobnú analýzu nad našimi dátami, aby sme navrhli čo najlepší algoritmus na automatickú extrakciu článkov. Tento algoritmus je založený na rozpoznávaní nadpisov a textov, a následnom priradzovaní jednotlivých textov k nadpisom. Vďaka našej metóde sme schopní odhaliť až 70% článkov.
3. Webová aplikácia
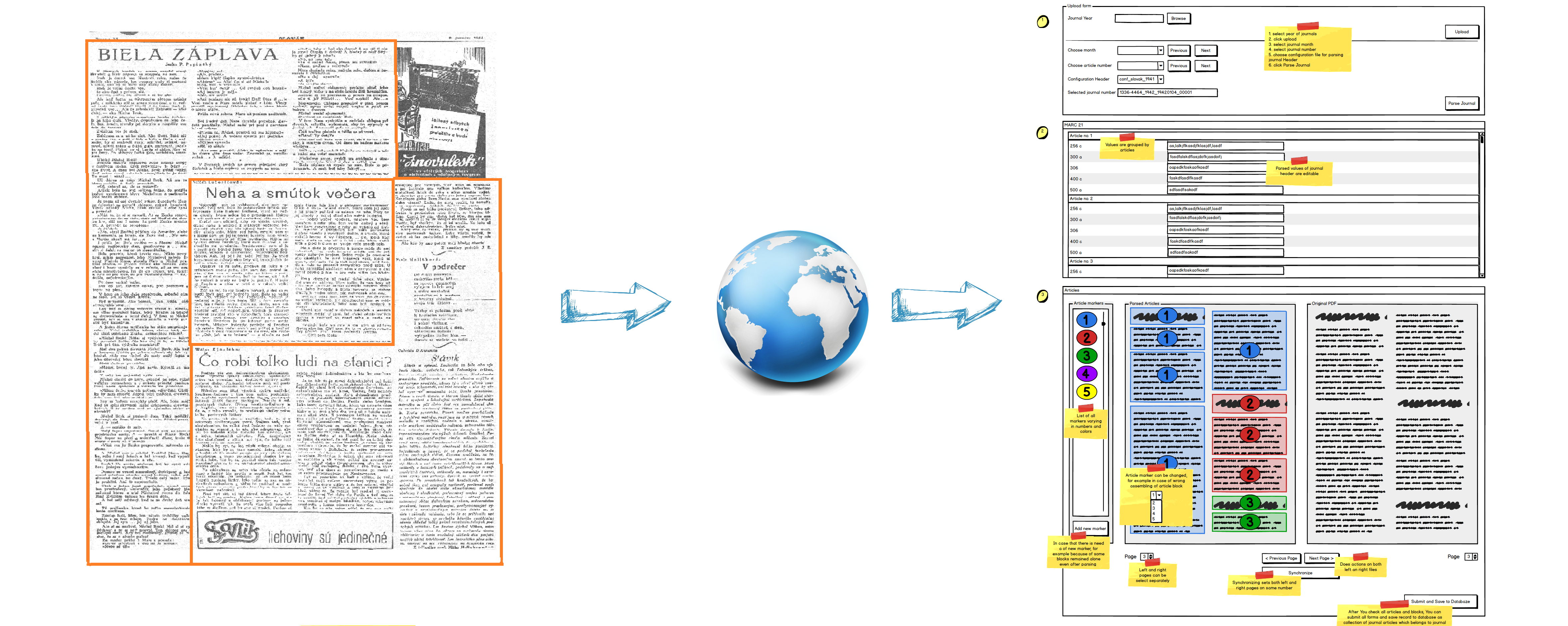
Po tom ako sú dáta spracované, sú poslané do webovej aplikácie, kde ľudia s odbornou znalosťou posúdia, či boli jednotlivé články správne vygenerované. V jednoduchom grafickom rozhraní sú zobrazené ako obrazové strany posudzovaného čísla, ako aj náš výsledok po spracovaní. Tiež sú tu knihovnícke informácie o jednotlivých článkoch vo formáte Marc21. Používateľ má možnosť okrem prehliadania naše výsledky aj upravovať, s cieľom nájsť a opraviť vzniknuté chyby, čím sa maximalizuje úspešnosť našej metódy.
4. Uloženie do databázy

Po ukončení práce v grafickom rozhraní sú všetky dáta uložené do textovej databázy ElasticSearch, ktorá má výhody pre ďalšie textové operácie, ktoré sa budú vykonávať pri aplikovaní sémantického vyhľadávania nad našim spracovaným datasetom.