Hrubý plán projektu je určený zadaním predmetu Tímový projekt a je opísaný v prvej tabuľke. Zjemnenie tohoto plánu sa nachádza v druhej tabuľke. Podrobnosti o plnení plánu v aktuálnom týždni sa nachádzajú v kapitole 5.
3, 8, 9, 12 - kontrolný týždeň v ktorom je nutné odovzdať dokumentáciu, prototyp, ...
Úlohy členov tímu sú organizované v dvoch tabuľkách. V prvej sa nachádzajú dlhodobé úlohy a role členov tímu, ktoré sú v súčasnosti identifikované. V druhej tabuľke, ktorá je aktualizovaná každý týždeň sú umiestnené aktuálne úlohy, ktoré členovia tímu v príslušnom týždni riešia.
Stretnutie č. 1 Tím č. 5 Dátum: 18. 10. 1999 Čas: 14:00 Miesto: d07b Účastníci: M. Makula, T. Milička, I. Noris, B. Vasilovčík, K. Vlasko Vedúci projektu: M. Bieliková, M. Smolárová Priebeh:
Dokumentácia
Ciele projektu
Úlohy do budúceho stretnutia:
Vypracoval: M. Makula
Stretnutie č. 2 Tím č. 5 Dátum: 26. 10. 1999 Čas: 10:00 Miesto: d07b Účastníci: M. Makula, T. Milička, I. Noris, B. Vasilovčík, K. Vlasko Vedúci projektu: M. Bieliková Téma stretnutia (podľa harmonogramu) : Analýza problému, hrubý návrh riešenia Vyhodnotenie úloh z predchádzajúceho stretnutia :
Ďalšie prebrané body:
Úlohy do ďalšieho stretnutia
Vypracoval: T. Milička Príloha A – Navrhovaná štruktúra stránky Stránka musí obsahovať tieto informácie:
Vypracoval: I. Noris Príloha B – Poznámky k systému CASETOOL
Vypracoval: T. Milička
Stretnutie č. 3 Tím č. 5 Dátum: 2. 11. 1999 Čas: 10:00 Miesto: d07b Účastníci: M. Makula, T. Milička, I. Noris, B. Vasilovčík, K. Vlasko Vedúci projektu: M. Bieliková Téma stretnutia (podľa harmonogramu): Analýza problému, hrubý návrh riešenia Vyhodnotenie úloh z predchádzajúceho stretnutia:
Ďalšie body stretnutia:
Úlohy do ďalšieho stretnutia:
Vypracoval: I. Noris Príloha – Navrhovaná štruktúra dokumentu (s korektúrou) Dokumentácia k projektu Zadanie Úvod + ciele + štruktúra celého dokumentu + tím Riadenie projektu
Produkt
Vypracovali: Matej Makula, Ivan Noris
Stretnutie s lekármi č. 1 Tím č. 5 Dátum: 2. 11. 1999 Čas: 17:00 Miesto: Fakultná nemocnica na Mickiewiczovej ulici Účastníci: M. Makula, T. Milička, I. Noris, B. Vasilovčík, K. Vlasko, M. Kucbel, J. Kovaľ, K. Krnáč Pedagógovia: P. Návrat, M. Bieliková, M. Smolárová Lekári: P. Záhon, P. Kučera Téma stretnutia: získavanie a upresňovanie informácií
Vypracovali: M. Makula, I. Noris Príloha - Proces transformácie údajov Súčasný stav:
Požadovaný stav:
Vzhľadom na popularitu ECCO formátu, lekári vyžadujú konverziu medzi novým formátom údajov a ECCO formátom. Z tohoto dôvodu je načrtnutá aj druhá alternatíva konverzie údajov pomocou ECCO formátu. Vypracovali: M. Makula, I. Noris
Stretnutie č. 4 Tím č. 5 Dátum: 9. 11. 1999 Čas: 10:00 Miesto: d07b Účastníci: M. Makula, T. Milička, I. Noris, B. Vasilovčík, K. Vlasko Vedúci projektu: M. Bieliková Téma stretnutia (podľa harmonogramu): Záverečné práce na dokumentácii Vyhodnotenie úloh z predchádzajúceho stretnutia:
Ďalšie body stretnutia:
Úlohy do ďalšieho stretnutia:
Vypracoval: Boris Vasilovčík
Etapa analýzy je nevyhnutnou súčasťou každého softvérového projektu. Jej cieľom je naštudovanie a pochopenie potrebných znalostí z problematickej oblasti, ktoré následne možno využiť v ďalších etapách životného cyklu projektu. Vzhľadom na charakter tohto projektu nebudú dokumenty k jednotlivým etapám úplne vyvážené. Táto časť bude pomerne rozsiahla, pretože ide o problematiku, ktorá je pre nás nová a dostali sme k dispozícii veľa informácií, ktoré sme mohli analyzovať. Jednotlivé kapitoly tejto časti sú logicky zoradené tak, aby aj čitateľ, ktorý sa v problematike nevyzná, mohol do nej rýchlo preniknúť. V prvej kapitole je stručne opísaný princíp EMG vyšetrenia. Ďalšie kapitoly opisujú rozšírený systém na spracovanie údajov z EMG vyšetrenia – CASETOOL a formát údajov používaný v tomto systéme. Súčasťou jednotlivých kapitol je aj stručné zhodnotenie resp. načrtnutie možností využitia získaných informácií. Elektromyografia (EMG) je súbor techník založená na elektrofyziologických testoch [1]. Tie sú zamerané najmä na skúmanie periférneho nervového systému, svalov a nervovo-svalových prenosov. EMG vyšetrenie je časovo náročné a pre pacienta nepríjemné. Pozostáva zo skupiny testov, pričom každý ma viacero hodnôt. Lekár musí uskutočniť často početné merania a získať viac ako sto rôznych hodnôt na analýzu každého výsledku vyšetrenia. Možnosti syntézy poznatkov a skúseností lekára závisia v širokom rozsahu od správnej voľby testov a procedúr. Keďže EMG vyšetrenie a diagnostika sú zložité, boli vyvinuté rozličné nástroje na podporu diagnostiky pomocou počítača. Tieto systémy (na analýzu signálov a podporu rozhodovania) umožňujú syntézu údajov z EMG vyšetrenia. Systémy na podporu rozhodovania sú vo všeobecnosti založené na znalostiach a poskytujú formuláciu EMG diagnózy z údajov získaných pri vyšetrení s využitím údajov v báze znalostí, ktoré sa získali pri predchádzajúcich vyšetreniach. Lekár vykonávajúci EMG vyšetrenie navrhuje jednu alebo viac hypotéz podľa predpokladanej diagnózy, klinických (symptómy, rizikové faktory, dedičnosť, choroby, užívané lieky) a prípadne neklinických údajov o pacientovi v čase vyšetrenia. EMG procedúra sa definuje podľa najpravdepodobnejšej hypotézy a možno ju zmeniť, ak sa nepotvrdí. Naplánovaná EMG procedúra sa tiež môže zmeniť v prípade špecifických podmienok vyšetrenia (rýchle vyšetrenie napr. na pohotovosti, vedomie pacienta, typ liečby). Už na základe týchto informácií je zrejmé, že výsledky EMG vyšetrenia ako aj procedúry, ktoré sa vykonávajú, závisia do značnej miery od lekára a jeho skúseností. V mnohých prípadoch dokonca aj sami lekári nie sú schopní zhodnúť sa na výslednej diagnóze napriek tomu, že majú k dispozícii údaje získané z EMG vyšetrenia. Pre štandardizáciu týchto vyšetrení resp. spôsobu ich vykonávania a určovanie diagnózy sa lekári v rámci projektu EMG stretávajú na pravidelných konferenciách, na ktorých diskutujú o problémových prípadoch. Na realizáciu ľubovoľného softvéru na podporu určovania diagnózy pacienta na základe výsledkov EMG vyšetrenia treba vytvoriť širokú bázu údajov z vyšetrení pacientov. Táto nemusí slúžiť priamo ako báza znalostí pre programy, ale aj nepriamo – poskytovať množstvo relevantných informácií pre lekárov. Lekári môžu napríklad vyhodnocovať údaje pomocou štatistiky alebo využívať ich na svojich stretnutiach. Výsledkom konkrétneho testu je iba hodnota, ktorú treba porovnať s normatívnymi hodnotami pre daný test. Tieto hodnoty sú rozličné pre rôzne oblasti (krajiny), vekové skupiny a pod. Získavajú sa na základe štatistík vyšetrení zdravých pacientov. Aj v tomto prípade by bolo možné použiť bázu údajov s výsledkami EMG vyšetrení.
Údaje získavané pri EMG vyšetrení Ako vyplýva z prvej časti, komunikácia lekárov z viacerých krajín vyžaduje predovšetkým dokonalé porozumenie výsledkov vyšetrení najmä z formálneho hľadiska. Preto bolo prvoradým cieľom navrhnúť štandardnú, medzinárodne uznávanú štruktúru údajov. Nasledujúca časť poskytuje informácie predovšetkým o hierarchii údajov získavaných pri EMG vyšetrení. Pri návrhu štruktúry údajov z EMG vyšetrenia bolo dôležité pokrytie všetkých anatomických štruktúr, vyšetrovacích techník a parametrov používaných lekármi z projektu ESTEEM. Okrem toho by dátová štruktúra mala byť schopná reprezentovať diagnostický proces EMG štúdie s možnosťou porovnania s jej inou interpretáciou. Údajová štruktúra bolo navrhnutá po viacerých iteráciách špecifikácie, implementácie a z hodnotení výsledných EMG štúdií. Prvá špecifikácia dátovej štruktúry bola založená na dotazníkoch o použitej metóde merania EMG. V týchto dotazníkoch lekári určili druhy meracích techník, zodpovedajúce anatomické časti a parametre, ktoré brali v úvahu pri interpretovaní nálezov.Údaje z EMG vyšetrenia sú rozdelené do troch častí.
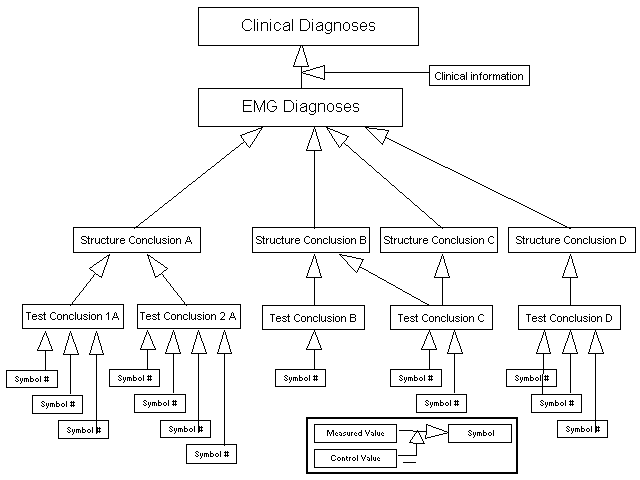
Všeobecné údaje Všeobecné údaje sú rozdelené na informácie o pacientovi, informácie z vyšetrenia a klinické informácie. Informácie o pacientovi obsahujú jeho identifikáciu, dátum narodenia, pohlavie, váhu a výšku. Informácie z vyšetrenia obsahujú identifikáciu lekára, dátum merania, počet rokov praxe a trvanie EMG vyšetrenia. Klinické informácie obsahujú dôvod pre odporučenie na vyšetrenie, zdroj odporučenia a polia pre informácie o dedičnosti, klinickej chémii, histológii, rádiológii, užívaných liekoch, klinických nálezoch a klinickej histórii. Namerané údaje Nemerané údaje pozostávajú z hodnôt získaných pri testovaní svalov, nervov, nervových segmentov a neuromuskulárnych zakončení. Pre každý zo 17 rôznych testov sú špecifikované množiny parametrov. Všetkých 17 techník môže mať spolu 122 parametrov. Najviac parametrov sa reprezentuje nameranými hodnotami a referenčnými odchýlkami. Niektoré parametre sa reprezentujú nasledovnými symbolmi: plný, redukovaný, diskrétny, signálna jednotka a bez odpovede. Pre každý typ testu sa určuje množina podmienok s cieľom opísať okolnosti, za ktorých sa test vykonal. Odvodené údaje Odvodené údaje tvoria diagnostickú hierarchiu (Obr. 1), ktorá reprezentuje jednotlivé kroky v procese stanovovania EMG diagnózy. V hierarchii sú zahrnuté (zdola nahor) nasledovné typy odvodených údajov: symbolic parameter values (SPV), pathophysiological test conclusions (PTC), pathophysiological structure conclusions (PSC), EMG-diagnoses (EMGD) a clinical diagnosis (CD). Obr.1: Hierarchická štruktúra určovania diagnózy pri EMG vyšetrení Najnižšia úroveň hierarchie zahŕňa SPV resp. symboly, ktoré vzniknú porovnaním nameraných a normatívnych hodnôt. SPV môže mať hodnotu normálnu, mierne zvýšenú, zvýšenú, mierne zníženú, zníženú, nedostatočnú alebo nešpecifikovanú. Pri spracovávaní EMG štúdií lekári používali individuálne normatívne hodnoty. Ďalšiu úroveň v hierarchii predstavujú PTC a PSC. Toto sú patofyziologické uzávery, koncept zavedený Fuglsang-Frederiksenom. PTC je definovaný ako najvhodnejší patofyziologický uzáver pre anatomickú štruktúru, ktorý sa môže odvodiť z úvah o nálezoch (SPV) pri jednom teste. PCS je definovaný ako najvhodnejší patofyziologický uzáver pre anatomickú štruktúru, ktorý sa môže odvodiť zo všetkých dostupných testov. PTC a PSC môžu nadobúdať hodnoty, ktoré závisia od druhu anatomickej štruktúry (svaly, nervy, nervové segmenty a neuromuskulárne zakončenia). Cieľom bolo jednoducho vytvoriť klasifikáciu použitím bežných výrazov. Výrazy ako „nedostatočný“ a „neuropatický“ by sa nemali používať súčasne. Výsledok PTC „nešpecifikovaný“ indikuje abnormalitu s nejasným dôkazom patofyziologickej špecifickosti alebo anatomickej lokalizácie. „Neuropatický“ indikuje abnormalitu nervu alebo nervového segmentu s nejasným dôkazom patofyziologickej špecifickosti. Ostrosť záverov PTC a PSC môže byť slabá, stredná alebo veľká a časový sled je odstupňovaný na akútny, progresívny a chronický. Druhá úroveň zhora v diagnostickej hierarchii sa skladá z jednej alebo viacerých EMGD. Tieto diagnózy sa odvádzajú z PSC, topografického rozloženia anatomických štruktúr a výsledkov štúdia EMG bez uvažovania klinických údajov. EMGD je teda druh umelej diagnózy odvodenej kombinováciou všetkých informácií z EMG štúdie okrem klinických informácií. Je definovaných 156 rôznych hodnôt EMGD. Najvyššou úrovňou diagnostickej hierarchie je CD. Tieto diagnózy sú odvodené z EMGD spolu zo všetkými klinickými informáciami (história, klinická chémia, klinické nálezy atď.). CD je reprezentovaná voľným textom a voliteľne kódom z medzinárodného kódovacieho systému ICD10.
Všeobecné informácie V rámci projektu EMG je nevyhnutná výmena údajov o vyšetreniach pacientov medzi jednotlivými lekárskymi pracoviskami. V rámci tejto komunikácie sa používa dátový formát ECCO, ktorý bude opísaný neskôr. Nástrojom pre prácu s týmto formátom sa stal systém CASETOOL, ktorý lekári hojne využívajú aj napriek tomu, že systém je už pomerne zastaralý a má mnoho nevýhod. Počítačový program CASETOOL bol vytvorený pre potreby uchovávania a spracovávania výsledkov EMG testov. Používa pevný formát súboru založenom na klinickej špecifikácii. Formát súboru je špecifikovaný v EMG komunikačnom protokole (ECP) zahŕňajúc zoznam kódov anatomických termov, PTC (pathophysiological test conclusion), PCS (pathophysiological structure conclusion) a EMGD (EMG-diagnosis). Program je implementovaný v Turbo Pascale pre MS-DOS s použitím objektovo-orientovaných princípov a knižnice Turbo Vision. Používateľské rozhranie je zložené z niekoľkých formulárov, medzi ktorými sa možno prepínať. Hodnoty zadané do formulárov sa transformujú do dátovej štruktúry v súbore. Opis používateľského rozhrania Na Obr. 2 je znázornené hierarchické rozčlenenie používateľských rozhraní systému. V ďalšom opíšeme jednotlivé formuláre (obrazovky), použité typy údajov a spôsob ich použitia.
Obr. 2: Rozčlenenie CASETOOL na jednotlivé formuláre
Všeobecné informácie (General data)
Tento formulár sa skladá z troch častí. Prvú tvoria všeobecné údaje o pacientovi. Zahŕňajú identifikačné číslo pacienta, dátum narodenia, výšku a váhu pacienta a pohlavie. Ďalšou časťou sú všeobecné informácie o vyšetrení. Tieto obsahujú kód laboratória, v ktorom sa EMG vyšetrenie vykonalo a analyzovalo; dátum a dĺžku trvania vyšetrenia; dĺžka praxe lekára vykonávajúceho EMG vyšetrenie (v rokoch). Poslednou časťou všeobecného formulára sú odkazy na jednotlivé testy, informácie o diagnóze a iné (non-EMG) informácie nesúvisiace s EMG. Ukážka všeobecného formuláru je na Obr. 3. 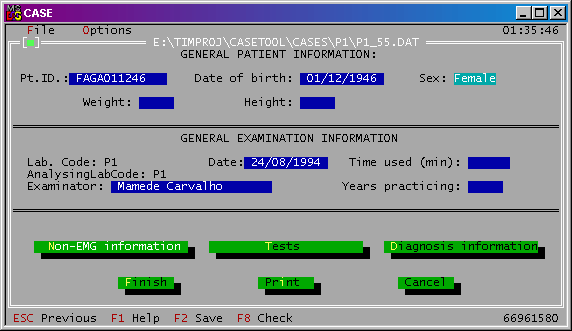
Obr. 3: Formulár so všeobecnými informáciami
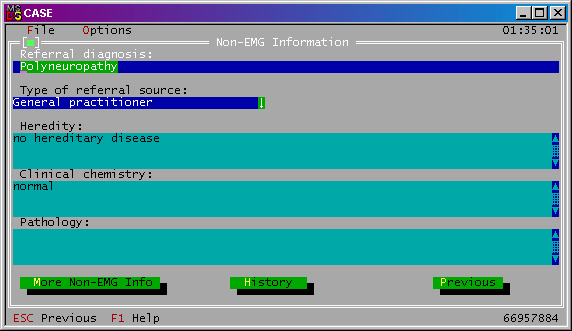
Iné informácie 1, 2 a História (Non-EMG information, History) Tieto formuláre obsahujú informácie, ktoré nemajú priamy súvis s EMG vyšetrením (Obr. 4). Prvý formulár obsahuje pole s diagnózou, s ktorou bol pacient poslaný na EMG vyšetrenie, zdroj diagnózy, dedičnosť, klinickú chémiu a patológiu. Ďalej obsahuje odkazy na formuláre Iné informácie 2 a História. Formulár Iné informácie 2 obsahuje položky z radiológie, o užívaných liekoch a nálezy z neurológie. Formulár História obsahuje jedinú položku, ktorá zachytáva informácie o predošlom vývoji choroby a počiatok výskytu jej symptómov. Všetky položky v týchto troch formulároch sú textové.
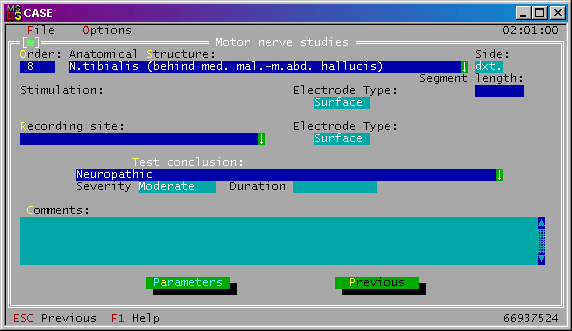
Obr. 4: Formulár Iné informácie 1 so svojimi položkami a odkazmi na ďalšie formuláre Zoznam testov (Tests) Tento formulár obsahuje zoznam vykonaných testov na pacientovi. Zoznam obsahuje poradové číslo testu, anatomickú štruktúru na ktorej bol daný test vykonaný, stranu a skrátené označenie testu. V tomto formulári je možné editovať, vložiť nový alebo zmazať už vykonaný test. Nový test sa volí výberom zo 17 ponúkaných. Po výbere sa dostaneme do formulára Štúdium motorických nervov. Štúdium motorických nervov (Motor nerve studies) Tento formulár (Obr. 5) obsahuje niektoré už spomínané informácie z predošlého formuláru a to poradové číslo testu, anatomickú štruktúru a vyšetrovanú stranu (ľavá/pravá). Ďalej obsahuje typy použitých elektród, výsledok testu, silu a dĺžku trvania odozvy. K testu možno pripojiť komentár. Z tohto formulára sa dostaneme do formuláru Parametre.
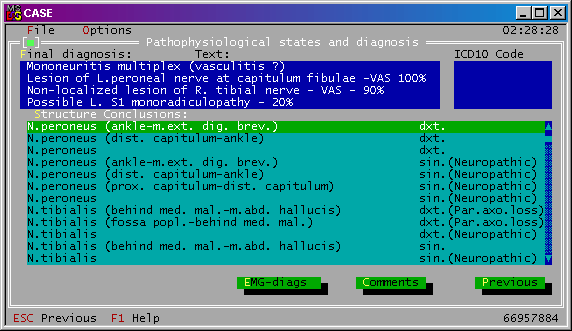
Obr. 5: Formulár Štúdium motorických nervov so svojimi položkami a odkazom na formulár Parametre Parametre (Parameters) V tomto formulári sa zadávajú hodnoty zmeraných parametrov. Štruktúra formulára sa mení v závislosti od typu vykonávaného testu. Spoločnou črtou je zápis nameraných hodnôt do stĺpcov. Lekár má možnosť zistiť percentuálnu odchýlku od normálových hodnôt a získať slovné vyhodnotenie zmeraného parametru. Diagnóza (Diagnosis information) Formulár sa skladá zo záverečnej diagnózy opísanej textom a medzinárodným ICD10 kódom (troj alebo päť miestny) a zoznamu testov ukončených štrukturálnym záverom, na základe ktorých sa určuje záverečná diagnóza. Lekár môže určiť aj viacero diagnóz percentuálnym ohodnotením ich pravdepodobnosti. Lekár vyberá diagnózu zo zoznamu predefinovaných diagnóz. K diagnóze možno pripojiť aj textový komentár. Po konzultácii s lekármi sme však zistili, že túto možnosť často nevyužívajú. Formulár Diagnóza je na obrázku č. 6.
Obr. 6: Formulár pre určenie konečnej diagnózy Nastavenie normálových hodnôt (Edit normal values) Tento formulár umožňuje nastaviť normatívne hodnoty (získané či už z literatúry alebo vyšetrením zdravých osôb). Nachádza sa tu meno testu pre ktorý chceme nastaviť normálové hodnoty, ďalej anatomická štruktúra, ktorú testujeme a parameter merania. Je možné si zvoliť formát zadania hodnôt a závislosť od určitého parametra. Formáty zadávania môžu byť hodnotou a limitom, hodnotou a rozsahom, hodnotou a percentuálnym rozsahom, lineárnou alebo logaritmickou funkciou. Parameter môže byť závislý od veku, výšky, pohlavia a dĺžky. Je možné zadať nové normálové hodnoty ako aj meniť už existujúce. Nedostatky Hlavným nedostatkom systému CASETOOL je jeho monolitická štruktúra, t.j. nie je modulárny. Preto je prakticky nemožné dopĺňať do systému ďalšie funkcie ani zmeniť údajový formát, s ktorým CASETOOL pracuje. Softvérový systém CASETOOL je zviazaný výlučne s dátovým formátom ECCO. Zdrojové súbory systému sú napísané v jazyku Pascal, ale aj napriek ich dostupnosti z nich nemožno vychádzať, pretože nie sú komentované. Formulár zo všeobecnými informáciami a vyšetrení nezachytáva možnosť zaznačenia opätovného vyšetrenia (napríklad o dva mesiace) do toho istého formulára (a teda ani dátového súboru). Na stretnutí s lekármi sme zistili, že až v 20% prípadoch ide o opakované vyšetrenie a preto by tu táto možnosť nemala chýbať. Pri výbere viacnásobných diagnóz spolu s ich percentuálnou pravdepodobnosťou vo formulári Diagnóza sa tieto automaticky nedopĺňajú do textového poľa. Diskutabilný je aj význam vizuálneho nastavovania percentuálnej pravdepodobnosti diagnózy. V tomto prípade sa však jedná iba o nedostatok funkčného rozhrania systému. Ako nedostatok systému CASETOOL (resp. ECCO formátu) možno považovať nejednoznačnosť textových položiek, nutnosť vyplnenia niektorých položiek (napríklad ICD10 kód) a malú zviazanosť zmien informácii v jednotlivých formulároch. Záver Podľa vyjadrení lekárov je filozofia systému CASETOOL v podstate dobrá, pretože je to veľmi jednoduchý a rozšírený systém. CASETOOL predstavuje iba editor údajov z EMG vyšetrenia, ktoré uchováva vo formáte ECCO a jednoducho ich transformuje do formulárovej štruktúry a tvorí tak rozhranie medzi používateľom a ECCO súborom. Aj keď by bolo zaujímavé rozšíriť systém CASETOOL o sieťovú podporu (možnosti práce v distribuovanom prostredí), prípadne o znalostné moduly, ktoré by podporovali proces stanovenia diagnózy, pre vyššie uvedené dôvody (najmä slabú modularitu a viditeľnosť) to nie je možné. Vzhľadom na to, že CASETOOL nepredstavuje znalostný systém, vedomosti získané jeho analýzou môžeme využiť najmä pri vytváraní používateľského rozhrania a určení spôsobu zadávania údajov z EMG vyšetrenia do vytváraného systému.
Formát údajov v systéme CASETOOL (ECCO) Systém CASETOOL pracuje s údajovým formátom ECCO, ktorý zahŕňa informácie o EMG vyšetrení. Tento formát sa používa na prenos údajov z EMG vyšetrení medzi jednotlivými EMG centrami. Momentálne posledná verzia je označená ako 3.2 [2]. Súbor tohto formátu je binárny a jeho dĺžka je premenlivá a závisí od počtu testov, ktorých výsledky sú v súbore uložené. Jeden súbor zodpovedá jednému vyšetreniu pacienta, ktoré môže byť tvorené viacerými testmi. Súbor je zložený z niekoľkých sekcií. Týchto sekcií je niekoľko druhov: Sekcia všeobecných informácií (General information data section) obsahuje údaje spoločné pre všetky testy, napr. údaje o pacientovi a pod. Jej označenie v rámci súboru je [000.0.0] až [004.0.0] Sekcia údajov vzťahujúcich sa k určitej anatomickej štruktúre (Anatomical structure specific data section) obsahuje zistené údaje o anatomickej sekcii X. Jej označenie v rámci súboru je [005.X.0] Sekcia dát získaných z EMG vyšetrenia (Examination technique specific data section ) obsahuje dáta získané z EMG vyšetrenia č. 1 až 17 na štruktúre X s poradovým číslom Y. Jej označenie v rámci súboru je [010.X.Y] až [173.X.Y] Všetky sekcie v dátovom súbore sú uložené za sebou, ako to znázorňuje nasledujúci obrázok:
2B 4B CRC – kontrolný súčet celého súboru okrem týchto dvoch bajtov Dĺžka – dĺžka celého súboru vrátane CRC a týchto štyroch bajtov
Každá sekcia je zložená z dvoch hlavných častí:
CRC – kontrolný súčet pre sekciu okrem CRC ID kód sekcie – číselné označenie sekcie [AAA.X.Y] Dĺžka sekcie – dĺžka sekcie v bajtoch vrátane hlavičky Číslo verzie – číslo verzie súboru vynásobené číslom 10 (napr. verzia 3.2 má číslo verzie 32) Opis sekcií [000.0.0] – Sekcia obsahujúca ukazovatele na zvyšné sekcie (pointer section). Táto sekcia slúži na lepšie vyhľadávanie sekcií v súbore a je povinná.[001.0.0] – Sekcia obsahujúca informácie o pacientovi, všeobecné informácie spoločné pre všetky testy a informácie netýkajúce sa EMG. Táto sekcia je povinná. [002.0.0] – Sekcia obsahujúca EMG diagnózu vo forme textu a príslušných kódov. Táto sekcia je nepovinná. [003.0.0] – Sekcia obsahujúca celkovú diagnózu vo forme textu a príslušných kódov. Táto sekcia je nepovinná. [004.0.0] – Sekcia, ktorá jednoznačne identifikuje všetky testy nachádzajúce sa v súbore. Sú tu zaznamenané: číslo testu, vyšetrovacia technika, anatomická štruktúra a pod. Táto sekcia je povinná v prípade, že niektorá iná sekcia používa niektorú anatomickú štruktúru X, inak je nepovinná. [005.X.0] – Sekcia obsahujúca celkové závery získané z vyšetrenia anatomickej štruktúry X vo forme textu alebo kódov. V súbore môže byť najviac jedna pre každú anatomickú štruktúru X a je nepovinná. [010.X.Y] až [013.X.Y] – 4 sekcie obsahujúce EMG údaje získané vyšetrovacou technikou 1 aplikovanou na anatomickú štruktúru X v teste č. Y. Obsahujú informácie o meracom prístroji, informácie o získaných signáloch, zhodnotenie a podobne. Sekcia [010.X.Y] je povinná a ostatné sú nepovinné. Prvé dve číslice v označení tvoria číslo vyšetrovacej techniky (01 až 17) a tretia označuje typ informácie o vyšetrení:
[020.X.Y] až po [173.X.Y] – Sekcie analogické ako [010.X.Y], len pre testy číslo 02 až 17. Sekcie [010.X.Y] až [173.X.Y] sú nepovinné a nachádzajú sa v súbore len v prípade, že bol vykonaný príslušný test. Štruktúra a dĺžka údajových častí jednotlivých sekcií je rôzna pre jednotlivé typy vyšetrení a je podrobne popísaná v dokumente ESTEEM Communication Protocol (A2010) vrátane príloh s vyznačením významu jednotlivých kódových označení.
Pri analýze doteraz používaného formátu údajov ECCO 3.2 sme dospeli k názoru, že pre ďalšie využitie nie je postačujúci a preto sme navrhli niekoľko iných alternatív formátu údajov. Dôvody nevhodnosti pôvodného formátu sú nasledovné: Chýba v ňom možnosť zaznamenať niektoré údaje, napríklad dátumy viacerých vyšetrení Nemožno s ním pracovať v iných systémoch, napr. použiť v systéme MS Access a práca s binárnym súborom je zložitejšia ako práca s textovým dokumentom Pre distribuované prostredie je vhodnejšie použiť databázu Celkovo možno konštatovať, že ECCO formát je z hľadiska štruktúry (obsahu) uchovávaných informácií vyhovujúci. Ťažisko problémov spočíva najmä v spôsobe uchovávania týchto údajov. Štruktúrovaný textový dokument Tento spôsob zápisu údajov získaných z EMG vyšetrení sa javí ako najjednoduchší. Jeho ďalšia výhoda spočíva v tom, že v takomto stave by sa dal ľahko prenášať cez sieť napr. pomocou štandardu XML a umožňuje tiež jednoduché spracovávanie a prehľadávanie z hľadiska implementácie. Jeho nevýhodou by mohla byť dĺžka samotného textového dokumentu, ktorá by bola určite väčšia ako dĺžka momentálne platného formátu ECCO 3.2. Ďalšia nevýhoda by mohla spočívať v tom, že v rámci manažmentu týchto textových dokumentov by bolo potrebné vytvoriť databázu samotných dokumentov kvôli lepšiemu hľadaniu a zápisu. Štruktúra textového dokumentu Samotný textový dokument by mohol byť rozdelený na časti (sekcie) podobne ako vo formáte ECCO 3.2, obsahoval by teda sekcie všeobecných informácií a sekcie konkrétnych informácií o jednotlivých vyšetreniach. Samotný zápis údajov by mohol byť realizovaný podobným spôsobom ako štandardné *.ini súbory. Jeden takýto textový dokument by obsahoval iba údaje o jednom pacientovi a teda každý pacient by mal svoj textový súbor. Príklad štruktúrovaného dokumentu [Section management] Sections=4 Pointers= ........ [Header information] Name=“Anonymous“ Sex=“Male“ Age=35 ....... [EMG diagnosis 1] Text=“EMG diagnosis: Presynaptic transmission failure....“ Code=10550 ...... ...... [EMG diagnosis n] Text=“EMG diagnosis: Presynaptic transmission failure....“ Code=10550 ...... [Final diagnosis 1] Text=““ Code= -1 ..... ..... [Final diagnosis n] Text=““ Code= -1 ..... [Test ID 1] Number_of_tests=2 Number_of_structures=1 Structures_codes=1740 Structures_names=“Extensor carpi radialis longus“ .... .... .... [Test ID n] .... [Structure conclusion 1740] Text=“...“ Code=10550 ..... ..... [Structure conclusion n] ..... [Examination 1.1] Date=01.11.1999 Examination_technique=.... Structure_code=1740 Segment_length=3 ..... [Examination 1.2] ..... ..... [Examination n.n] ..... Ako vyplýva z príkladu, tento zápis je prehľadný a jednoduchý, avšak takto vytvorený súbor by mal určite väčšiu dĺžku ako súbor v doterajšom ECCO formáte. Určitá optimalizácia by sa dala dosiahnuť použitím skratiek, alebo iba písaním kódov bez textov, napr. namiesto Date=01.11.1999 by sa písalo iba 01.11.1999 a podobne. Taktiež sa ponúka možnosť namiesto nami navrhnutej štruktúry vytvoriť priamo dokument formátu XML, čo by umožnilo ešte jednoduchšiu manipuláciu pri prenose cez sieť.
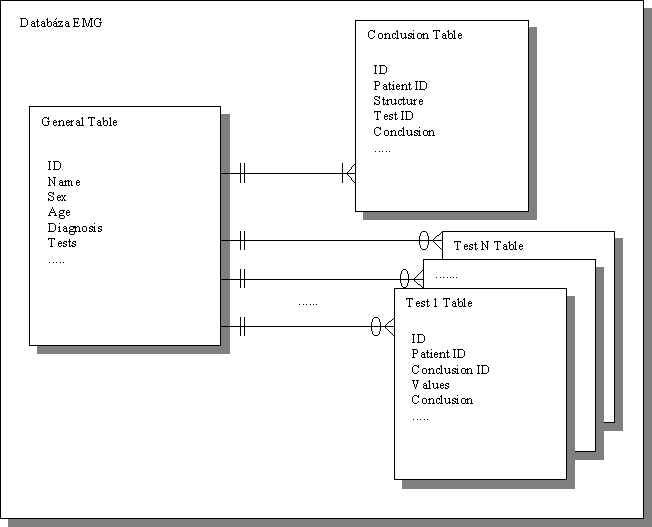
Databáza vytvorená v Microsoft Access Databázový systém MS Access je veľmi silný nástroj na tvorbu databáz a keďže údaje získané z EMG vyšetrení budú uchovávané v databázach, možno použiť aj tento systém. Výhody pri použití tohoto systému spočívajú v podpore jazyka SQL, možnosť prenosu dokumentov pomocou XML a tiež možnosť priameho spracovania týchto údajov v prostredí MS Office. Nevýhody tejto alternatívy sú: veľká zložitosť samotnej databázy, vysoké požiadavky na hardvérové a softvérové vybavenie lekárskych pracovísk a tiež samotný fakt neprenositeľnosti databázy na rôzne platformy (napr. UNIX). Štruktúra databázy Pri návrhu štruktúry databázy sme podobne ako v prípade štruktúrovaného textu vychádzali zo štruktúry doteraz používaného formátu ECCO 3.2. Databáza by mohla obsahovať pevne stanovený počet tabuliek a to tak, aby každá sekcia mala svoju tabuľku. Databáza by obsahovala údaje pre viacerých pacientov na rozdiel od štruktúrovaného textu, ktorý obsahuje iba údaje o jednom pacientovi. Základom by bola tabuľka (Obr. 7), ktorá by obsahovala údaje o pacientoch a ich diagnózach (aby sa dalo vyhľadávať aj podľa diagnózy) a tiež odkazy do ostatných príslušných tabuliek. Táto tabuľka by sa mohla nazývať napr. “General Table“. Ďalej by sa v databáze nachádzali tabuľky, ktoré by určovali, aké testy a na akých štruktúrach sa vykonali spolu s hodnotením týchto testov a štruktúr (obdoba sekcií [004.0.0] a [005.X.0]). Eventuálne by tieto tabuľky mohli byť zlúčené do jednej. Jej názov by mohol byť napr. “Conclusion Table“. Okrem tabuliek “General“ a “Conclusion“ by sa v databáze nachádzalo 17 tabuliek testov (pre každý test jedna). Tieto by obsahovali údaje o teste, namerané hodnoty a podobne. Ich názov by mohol byť napríklad “Test 1 Table“. Jeden pacient môže mať viac záznamov vo všetkých tabuľkách okrem tabuľky “General“. Z toho teda vyplýva, že vzťahy medzi tabuľkami budú 1 ku N. Takto štruktúrovaná databáza by mala aj tú výhodu, že by bolo možné vyhľadávať pacientov podľa vykonaných testov a tiež by nebolo treba prenášať napríklad údaje z testov, ktoré nie sú potrebné. Nasledujúci obrázok predstavuje nami navrhnutú databázu:
Obr. 7: Úvahy o dátovom modely Pri EMG vyšetrení môže mať jeden prípad stanovených aj viacero diagnóz. Tento problém by sa dal riešiť dvoma spôsobmi:
Jeden pacient môže mať priradený ľubovoľný počet diagnóz, čo je však nevýhodné v tom, že sa zvýši zložitosť databázy. Výhodnejšia bude pravdepodobne prvá alternatíva, pretože jeden pacient nemá obvykle viac ako 5 diagnóz a teda by bolo zbytočné zvyšovať zložitosť databázy. Na záver treba poznamenať, že tento obrázok slúži iba na znázornenie možností transformácie údajov z ECCO formátu do databázy, pričom výsledná štruktúra databázy môže byť odlišná, resp. prepracovaná. Analýza formátu XML Jazyk XML sa najčastejšie spája s prostredím www ako nový štandard, ktorý má v najbližšej dobe nahradiť široko používaný jazyk HTML. Preto sa teda ponúka otázka, ako možno aplikovať XML v projekte, ktorý len okrajovo súvisí s prostredím www. Pravda je taká, že XML je navrhnutý pre oveľa širšie využitie a to najmä v oblastiach výmeny údajov medzi nezávislými aplikáciami. Pre dobré pochopenie významu XML je však potrebné nezameriavať sa len na oblasť výmeny údajov, ktorá je pre náš projekt najvhodnejšia, ale venovať sa aj využitiu tohoto jazyka v prostredí www. Jazyk HTML bol odvodený od štandardu SGML ako jeho aplikácia pre publikovanie dokumentov na www [3]. Z pôvodného zložitého jazyka prevzal hlavne syntax, teda značky v tvare <ZNAČKA ATRIBÚT=”HODNOTA”>. V tomto jazyku sa odzrkadlila snaha oddeliť obsah dokumentov od formátovania – teda grafického zobrazenia, čoho dôkazom bola aj odlišné znázornenie bežných značiek v rôznych prehliadačoch (použitím iných fontov, odsadení, farieb, …). Avšak komercionalizácia Internetu a potreba tvorby graficky zaujímavých a príťažlivých stránok vyústila do nesprávneho používania tohoto jazyku vývojármi. Pri vytváraní dokumentov, bolo hlavným cieľom dostať na obrazovku pomocou jazyka HTML príťažlivý obsah, bez ohľadu na štruktúru a význam použitých značiek. Vďaka tomu nové verzie HTML, stratili význam všeobecného opisného jazyka, ale stále viac konvergovali k jazyku pre opis formátovania dokumentu. Ale aj napriek týmto problémom sa konzorcium W3C snaží navrátiť jazyku HTML pôvodný význam, pomocou zavedenia štruktúrovaného formátovania (napr. CSS – kaskádové štýly), čo však s veľkou pravdepodobnosťou neprinúti vývojárov k správnemu používaniu tohto jazyka. Tieto dôvody vniesli potrebu zavedenia nového štandardu, ktorý by neopisoval formátovanie dokumentu, ale jeho obsah. Význam jazyka XML možno najlepšie opísať na praktickom príklade:. <vyrobok> <nazov>Hifi veža . . .</nazov> <cena>8356</cena> <mena>Sk<mena> </vyrobok> Ak by sme uvedené fakty zapísali pomocou jazyka HTML, síce by sme si vedeli predstaviť, ako budú údaje znázornené, ale automatický robot určený na vyhľadávanie informácií by zrejme z použitých značiek veľa informácií nezískal. Ak je však záznam uvedený vo formáte XML, robot by na základe použitých značiek mohol informácie indexovať omnoho rozumnejším spôsobom. Dôležitým momentom je aj fakt, že dokument v XML v sebe nenesie žiadny opis formátovania a tento musí byť zadefinovaný nezávisle pomocou štýlov, ktorými zadefinujeme znázornenie jednotlivých značiek. Výhodou je to, že dokument štýlov je od dokumentu XML oddelený a preto môže viac XML dokumentov zdieľať rovnaký štýl. Hlavný prínos formátu údajov XML spočíva v tom, že okrem samotných údajov sa v dokumente nachádza aj informácia o ich význame. Vďaka tomu je konverzia do iných formátov jednoduchá a môže prebiehať automaticky. Na obrázku 8 sú znázornené rôzne typy dokumentov v závislosti od množstva „energie“, ktorú v sebe nesú. Pri konverzii informácií do foriem uvedených na vrchu pyramídy, je nutné vynakladať viacej energie, ktorú potom z tejto formy môžeme “uvoľňovať“, prostredníctvom jednoduchšej konverzie do ľubovolného formátu [4]. Obr. 8: XML a “množstvo” energie [4] Z hľadiska nášho projektu sa teda črtá možnosť transformovať ECCO, resp. nový formát údajov do ekvivalentnej štruktúry v jazyku XML. <vysetrenie>
...
</vysetrenie> Takúto organizáciu informácií pravdepodobne nemožno uchovávať na najnižšej úrovni, pretože pre distribuované prostredie je efektívnejšie použitie databázy. Na druhej strane tento alebo podobný formát údajov v XML možno použiť ako konvenciu do budúcnosti pre výmenu údajov medzi ďalšími aplikáciami pracujúcimi nad údajmi z EMG vyšetrenia. Z tohoto pohľadu sa javí ako výhoda možnosť jednoduchého dodefinovania prvkov najmä z hľadiska flexibility formátu do budúcnosti. V praxi by bolo možné transformovať údaje z nášho systému do formátu XML a poskytovať ich množstvu nezávislých aplikácií ako rozsiahlu bázu prípadov. Za nevýhodu tohoto formátu možno považovať určitú mieru redundancie, ktorá však v súčasnosti nie je rozhodujúcim faktorom pri výbere. Taktiež je nutné pri vstupe údajov v XML do systému použiť “inteligentný modul“ - parser, ktorý je schopný získať jednotlivé údaje z formátu XML.
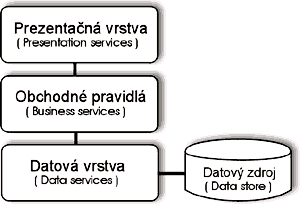
Architektúry databázových systémov Existuje viacero typov architektúr databázových systémov. Medzi základné architektúry patria dvojvrstvová architektúra s tučným klientom, dvojvrstvová architektúra s tučným serverom, trojvrstvová architektúra a Internet (intranet) architektúra [5]. Jednotlivé architektúry sa od seba líšia usporiadaním vrstiev, z ktorých sa skladajú. Týmito vrstvami sú prezentačná vrstva, obchodné pravidlá a dátová vrstva. Každá z vrstiev má svoju špecifickú úlohu. Prezentačná vrstva – zabezpečuje prezentáciu dát pre klienta (používateľa programu). Zobrazuje mu dáta a formuláre, umožňuje mu ovládať beh programu. Je to vlastne samotné používateľské rozhranie. Vrstva obchodných pravidiel – má na starosti logiku. Definuje ako, kde a ktoré dáta slúžia pre ktorú časť prezentačnej vrstvy, resp. ako a s ktorými údajmi pracovať podľa požiadaviek prezentačnej vrstvy. Ide vlastne o súhrn operácií a pravidiel, ktoré môže používateľ pomocou prezentačnej vrstvy uskutočniť. Dátová vrstva – ukladajú a spracovávajú sa v nej dáta. Táto vrstva má za úlohu fyzické ukladanie dát, ich spracovanie, údržbu. Nemožno ju ovládať priamo z prezentačnej vrstvy. Nevýhodou dvojvrstvovej architektúry s tučným klientom a dvojvrstvovej architektúry s tučným serverom je nerozloženie záťaže medzi klienta a server. V prvom prípade je celá aplikácia napísaná ako monolitický celok. Prezentačná vrstva je priamo zviazaná s obchodnými pravidlami. Kvôli tomu klient značne zaťažuje sieť, pretože väčšinou musí dostať na svoju stranu takmer všetky dáta, ktoré potrebuje. Modifikácia a rozširovanie takejto aplikácie je veľmi ťažké. Toto riešenie je nevhodné pre distribuovaný prístup k databáze. V druhom prípade je väčšina záťaže na strane servera. Výkonnosť takéhoto riešenia priamo závisí od počtu klientov a výkonu samotného servera. V prípade veľkého počtu klientov sa takéto riešenie neodporúča. Avšak v prípade, že počet klientov je konečný a poznáme výkon a robustnosť servera, môžeme použiť tento typ architektúry, dokonca v niektorých prípadoch je to jediné možné riešenie. V súčasnosti najviac používanými architektúrami sú trojvrstvová architektúra a Internet architektúra. Trojvrstvová architektúra Trojvrstvová architektúra umožňuje ľubovoľne rozširovať a modifikovať aplikáciu bez vážnejšieho narušenia jej logickej hierarchie a funkčnosti (Obr. 9). Takéto riešenie môže byť distribuované a umožňuje definovať niekoľko prezentačných vrstiev bez závislosti na ostatných vrstvách. Väčšina moderných komerčných aplikácií je založená práve na tomto type architektúry. Veľkou výhodou je nezávislosť jednotlivých vrstiev.
Obr. 9: Trojvrstvová architektúra [5] Toto riešenie výborne rozkladá záťaž medzi server a jednotlivých klientov. Ako každý model architektúry, aj trojvrstvový model má niekoľko nevýhod. Jednou z nich je obtiažnejšia údržba a spravovanie aplikácie, nakoľko ide o viaceré komponenty. Avšak takéto riešenie umožňuje skladať aplikácie z rôznych komponentov od rôznych dodávateľov bez toho, aby dochádzalo k chaosu a neprehľadnosti. Dôležitou úlohou pri návrhu takejto architektúry je správna voľba jednotlivých komponentov a ich vzájomnej interakcie.
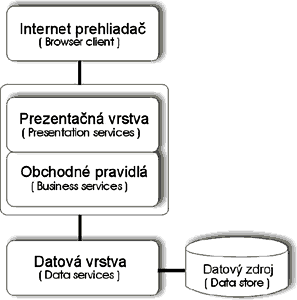
Internet (intranet) architektúra Obrovský rozmach používania Internetu má za následok vznik novej architektúry. Internet architektúra je najmladšia a v súčasnosti najdynamickejšie sa rozvíjajúca. Táto architektúra je podobná trojvrstvovej architektúre (Obr. 10). Jediným rozdielom je presun časti prezentačnej vrstvy do strednej časti k obchodným pravidlám. Dôvodom tohoto presunu je bezpečnosť a špecifický spôsob práce na Internete. Neznamená to však, že by tieto dve časti boli spojené. Ide iba o presun prezentačnej vrstvy na stranu servera tesne k obchodným pravidlám.
Obr. 10: Internet (intranet) architektúra [5] Najväčšou výhodou tejto architektúry je, že umožňuje používať aplikáciu komukoľvek, kto má Internetový prehliadač. Pracovať s takouto aplikáciou je možné všade tam, kde je pripojenie na Internet. S používania Internetu vyplývajú aj viaceré problémy. Ide hlavne o rýchlosť takejto aplikácie. Tá závisí od rýchlosti Internetu, ktorá je vo väčšine prípadov nedostatočná. Druhým veľkým problémom je fakt, že s takouto aplikáciou môže v jednom okamihu pracovať niekoľko tisíc užívateľov, čo kladie enormné nároky na spracovanie takejto aplikácie. Vyplýva z toho nutnosť dobrého návrhu takejto aplikácie.
Zhrnutie Pri tvorbe databázového systému je nevyhnutná správna voľba architektúry systému, ktorá závisí od konkrétneho problému. Rôzne problémy si vyžadujú rôzne modely architektúry systému, pričom ten istý model môže v jednom prípade znamenať najefektívnejšie riešenie a v inom prípade môže byť úplne nevhodný. Pri tvorbe distribuovaných databázových systémov je najvhodnejšie použiť model trojvrstvovej architektúry systému alebo Internet architektúry.
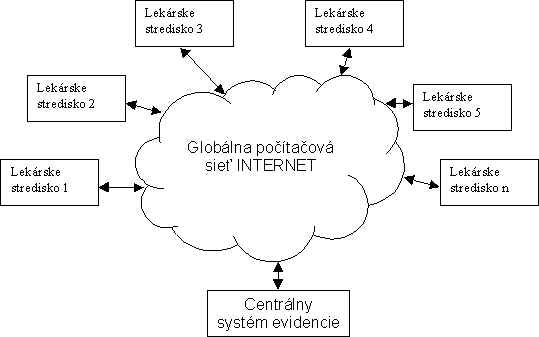
V etape špecifikácie sa stanovujú požiadavky na vytváraný systém. Možno ich rozdeliť na funkcionálne (zaoberajú sa funkcionalitou systému) a nefunkcionálne (stanovujú ohraničenia na systém). Vytváranie špecifikácie bolo charakteristické obmedzenými znalosťami členov tímu o riešenej problematike. Preto bolo nevyhnutné, aby sa uskutočnili stretnutia s lekármi, ktorých cieľom bolo získať základný prehľad o problémovej oblasti. Z prvého stretnutia vyplynul najmä nefunkcionálne požiadavky na systém, pričom lekári nemajú veľmi jasnú predstavu o jeho funkciách. To je jeden z hlavných dôvodov, prečo sa v tejto časti nachádzajú iba predbežné požiadavky, ktoré vyplynuli z kontextu systému a diskusie s lekármi. V tejto časti sa postupne zaoberáme kontextom systému, z ktorého vyplynie prvá množina požiadaviek na systém. Túto množinu rozšírime o ďalšie požiadavky získané počas diskusie s lekármi a na základe výslednej množiny sa pokúsime opísať riešenie, ktorým tieto požiadavky možno splniť. Vzhľadom na charakter riešenej problematiky je evidentné, že na celkové umiestnenie systému sa možno pozerať z viacerých uhlov pohľadu. V hrubom priblížení možno predpokladať, že sa celý systém nachádza v prostredí viacerých lekárskych pracovísk (Obr. 11). Základnou štruktúrou zabezpečujúcou komunikáciu medzi nimi je v našom prípade globálna počítačová sieť Internet, pričom jednotlivým pracoviskám bude náš systém umožňovať zdieľanie údajov.
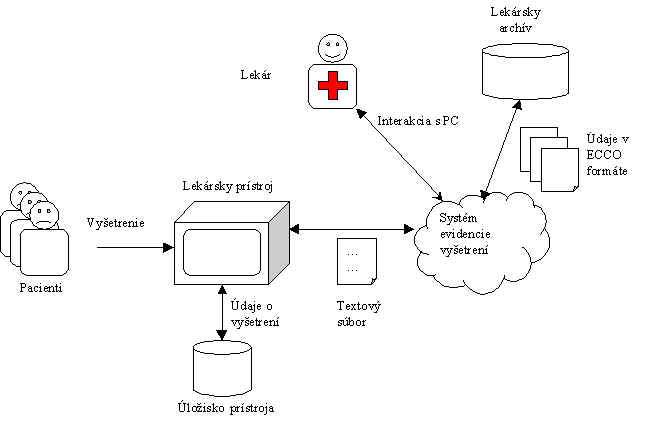
Obr. 11: Hrubý náčrt kontextu systému Na tejto úrovni abstrakcie existuje viacero faktorov ovplyvňujúcich výsledné požiadavky. Ak budú lekárske strediská k systému pristupovať iba z jednej krajiny, budú požiadavky na systém zrejme menšie, ako keby k nemu pristupovali z viacerých krajín. Medzi oboma prípadmi však existuje paralela - je zrejmé, že pôjde v podstate iba o rozšírenie množiny požiadaviek. To nám umožní navrhnúť a implementovať riešenie, ktoré aplikujeme na jednu krajinu (napr. Slovensko) a neskôr ho rozšíriť na širšie merítko (Európa). To však vyžaduje, aby sme túto možnosť zohľadnili už pri návrhu. Zrnitosť pohľadu na systém zmenšíme ak sa zameriame iba na prostredie lekárskeho pracoviska a jeho interakcie z okolím (Obr. 12). Prepojenie systému s okolím predstavujú tri rozhrania s externými entitami. Tie tvoria: Obr. 12: Zjemnený kontext systému Lekársky prístroj získava údaje priamo z meracích sond a uchováva ich v internom úložisku údajov. To obsahuje okrem údajov zo sond aj údaje o pacientovi, dátume vyšetrenia a pod. Prístroj je schopný údaje o vyšetrení vytlačiť alebo exportovať vo forme textového súboru. Tento súbor tvorí prvé rozhranie s naším systémom. Druhé rozhranie predstavuje vyšetrujúci lekár, ktorý zadáva údaje z vyšetrenia priamo do systému. V tomto rozhraní by mal mať možnosť aj dopĺňať informácie, ktoré nemožno získať z lekárskeho prístroja, prípadne ich modifikovať. Keďže predpokladáme existenciu archívov výsledkov vyšetrení, treba umožniť aj importovanie a exportovanie týchto údajov do systému resp. zo systému. V prípade, že sa archív uchováva v textovej (tlačenej) forme, o prenos údajov musí vykonať lekár manuálne (cez druhý typ rozhrania). Ak sú údaje v elektronickej forme, zvyčajne ide o dáta v ECCO formáte, ktorých importovanie resp. exportovanie možno realizovať programovo. Prvú množinu požiadaviek možno odvodiť z jednotlivých pohľadov na kontext systému: Požiadavky pre hrubý kontext systému:
Požiadavky pre zjemnený kontext systému:
Druhá množinu požiadaviek vyplýva z diskusie s lekármi:
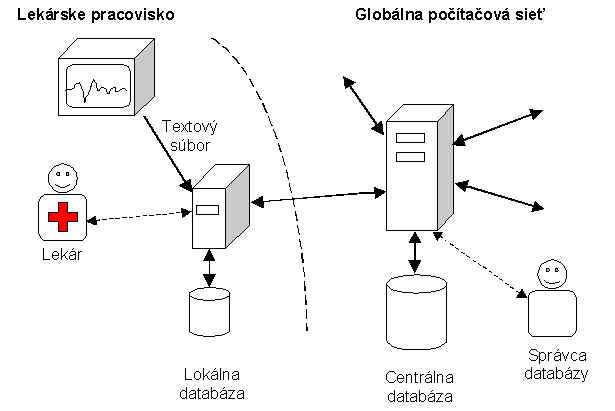
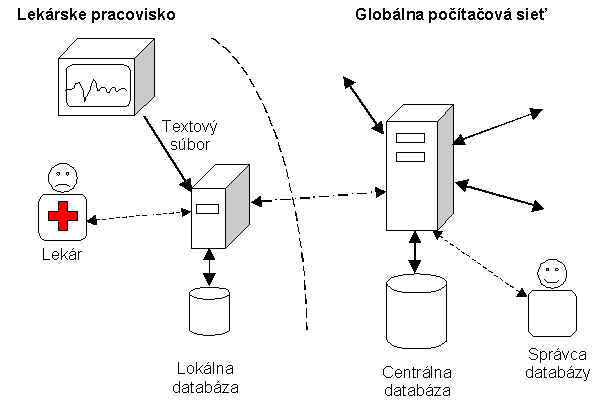
Pri štandardizovaní meracích techník a procesu stanovovania EMG diagnózy vzniká potreba flexibilnej komunikácie medzi lekármi. Bolo by dobré umožniť organizáciu elektronických on-line alebo off-line diskusií. To však nie je primárnou požiadavkou na vytváraný systém. Keďže proces stanovovania EMG diagnózy je náročný proces a v súčasnosti nie sú známe všetky závislosti medzi jednotlivými zložkami údajov z vyšetrenia, ani samotní lekári nevedeli špecifikovať množinu funkcií nad získanými údajmi. Filozofia celého projektu by mala spočívať vo vytvorení otvoreného systému pre evidenciu EMG vyšetrení so základnými operáciami ako sú vytvorenie, modifikácia, zrušenie záznamu, pričom ďalšie operácie by boli implementované až po ďalšom dodefinovaní požiadaviek. V tejto časti sa nachádzajú prvé predstavy návrhu systému, ktoré vychádzajú z doteraz získaných informácií. Nami prezentovaný návrh nie je prepracovaný do úplných detailov, ide skôr o hrubú koncepciu systému, ktorý by spĺňal doteraz identifikované požiadavky. V nasledujúcich kapitolách opíšeme náš návrh architektúry a možnosti jeho zovšeobecnenia. Čiastočne sa budeme zaoberať aj funkciami, ktoré by mali byť opísané v časti Špecifikácia, ale z dôvodu závislosti na architektúre sme ich načrtli až tu. Iné alternatívne koncepcie sú opísané v záverečnej kapitole tejto časti. Aby sme splnili požiadavky na systém, navrhli sme nasledujúci model architektúry. Jeho základnou črtou sú dva typy databáz, jedna centrálna a viacero lokálnych. Centrálna databáza zhromažďuje výsledky vyšetrení z určitého regiónu a je umiestnená v prostredí Internetu. Pomocou siete sa do nej importujú údaje z lokálnych databáz. Lokálna databáza je fyzicky umiestnená na lekárskom pracovisku, pričom jej trvalé pripojenie na Internet nie je nutnou podmienkou. Jej úlohou je zhromažďovať údaje, s ktorými lekár pracuje, resp. ho z nejakej príčiny zaujímajú. Na lokálnom počítači sa vykonáva aplikácia, ktorá spracováva údaje nad lokálnou databázou. Umožňuje importovať resp. exportovať výsledky vyšetrení v ECCO formáte, načítavať údaje z meracieho prístroja, ukladať a modifikovať ich v lokálnej databáze. Lekár má možnosť pripojiť sa prostredníctvom aplikácie na centrálnu databázu a zaslať alebo získať údaje o vyšetreniach. Architektúra s lokálnou a centrálnou databázou umožňuje efektívnu prácu v on-line aj off-line režime (Obr. 13, Obr. 14). Pri off-line režime lekár nevyužíva trvalé, ale iba občasné pripojenie na Internet. V takomto prípade môže lekár pracovať s lokálnou databázou bez iných obmedzení. Význam zahrnutia tohto režimu bude zrejmý z funkcií systému resp. možných scenárov použitia. (On-line / Off-line režim)
(iba On-line režim)
Z uvedeného vyplýva, že bežná prevádzka systému pozostávajúca z vyšetrení a úpravy lokálnej databázy nevyžaduje prácu v on-line režime. Napríklad pri EMG vyšetrení sa použijú funkcie automatická konverzia údajov z meracieho prístroja a prípadne modifikácia údajov vyšetrenia, ktoré nevyžadujú on-line mód. Tento sa použije iba pri zasielaní vyšetrení do centrálnej databázy (resp. ich načítaní).
Obr. 13: On-line architektúra systému Normatívne hodnoty Aby sme pokryli možnosť zberu normatívnych hodnôt čo najjednoduchšie, rozhodli sme sa evidovať normatívne aj ostatné vyšetrenia, v tej istej databáze (databázovej štruktúre). Týmto sú všetky údaje zahrnuté v jednom systéme, pričom na identifikáciu typu vyšetrenia môže slúžiť napríklad výsledná diagnóza. Normatívne vyšetrenia sa potom môžu postupne zbierať v lokálnej databáze (off-line režim), pričom v určitých časových intervaloch budú zasielané do centrálnej databázy. Čo treba zohľadniť Nevýhodou navrhovanej architektúry je nízka robustnosť. Pri poškodení centrálnej databázy môže dôjsť k strate informácií, čo bude nutné riešiť pravidelným zálohovaním centrálnej databázy. Toto riešenie vyžaduje tiež autorizáciu prístupu lokálnych aplikácií k centrálnej databáze, pretože tieto majú možnosť pridávať údaje. Pre tento účel musí existovať správca, ktorého úlohou bude udeľovať prístupové práva a vykonávať už spomenuté zálohovanie databázy. Vzhľadom na potrebu odstraňovania neúplných, nesprávnych (v zmysle zle vykonaného merania a pod.) alebo neaktuálnych údajov, pričom túto operáciu môže vykonávať iba lekár – špecialista, nie je nutné aby správcu centrálnej databázy predstavovala iba jedna osoba.
Obr. 14: Off-line architektúra systému Nami navrhovaná architektúra vychádza z centralizovaného prístupu. Jednotlivé lokálne aplikácie sa pripájajú na jedinú centrálnu databázu, pričom medzi sebou navzájom nekomunikujú. Alternatívu predstavuje čiastočne decentralizovaný prístup s viacerými „centrálnymi“ databázami, pričom každá obsahuje informácie z inej geografickej oblasti (pre ktorú slúži ako centrálna databáza). V tomto prípade je nutné vytvoriť register týchto databáz, ktorý by umožnil lokálnym aplikáciám vybrať si vhodnú databázu. Tento princíp by sa dal aplikovať pre rozšírenie projektu zo Slovenska na Európu. Na záver treba poznamenať, že existujú aj iné alternatívy riešení, ktoré by bolo možné využiť pri návrhu. Pri plne decentralizovanom prístupe by neexistovala žiadna centrálna databáza, ale iba register lekárskych stredísk, resp. databáz zapojených do projektu. V tomto prípade by však neexistoval uzol obsahujúci všetky EMG vyšetrenia a na ich lokalizáciu by bolo potrebné špeciálne spracovanie. Výhodou by bolo, že za svoje údaje by boli zodpovedné jednotlivé uzly a nebolo by treba riešiť otázku prístupových práv. Výhodou je aj vyššia robustnosť architektúry. Problémy by spôsobil režim off-line, pretože by údaje príslušnej databázy neboli k dispozícii. Ďalšie možnú alternatívu predstavuje replikácia údajov v lokálnych databázach. V tomto prípade by bol obsah lokálnej a centrálnej databázy rovnaký, čo by však malo za následok zvýšenie hardvérových nárokov a potrebu synchronizácie. Výhodu predstavuje väčšia rýchlosť prístupu k údajom. [1] Ziébelin, D. – Vila, A. – Rialle, V. NEUROMYOSYS: a diagnosis knowledge based system for EMG. Université Josheph Fourier Grenoble, France. [2] Jakobsen, L. S. – Fog, B. – Talbot, A. ESTEEM Communication Protocol, Tech. Report, 1993 [3] Laurent, S. Tvorba internetových aplikací v XML. Computer Press, Brno, 1999 [4] Kosek, J. XML: eXtensibile Markup Language. Zdroj na WWW: http://www.kosek.cz/clanky/xml/xml-uvod.html, 1999[5] Kulla, V. Programovanie s ADO. Zdroj na WWW: http://dev.gratex.sk/UfoBook, 1990 |